
This video will guide you through the steps to set up an SFTP server backed by S3 on AWS in only 33 minutes using Transfer Family. Alternatively, you can use the written instructions (and code snippets) below to set up your S3-backed SFTP Server on AWS the original way.
This kind of cloud solution used to be reserved for large enterprises with armies of network engineers. Now, however, just about anyone can set up an AWS SFTP Server with Amazon S3. Just follow these four steps, as seen in the video above:
- Create a secure server using AWS SFTP.
- Set up and connect resilient storage for your server with Amazon S3.
- Create users and manage server access.
- Connect to the server to upload and download files.
As mentioned, the full post below is still completely up to date. It might even be the best option for experienced cloud engineers who want to avoid the premium price tag attached to Transfer Family's service.
---
Fade In: Background Info on AWS SFTP Server
There are tutorials on the internet of setting up SFTP servers in Linux. There are also tutorials out there for using S3 as a mounted file system. This tutorial sets out to combine these two concepts in addition to setting up a fault-tolerant, highly-available environment in which to deploy your resulting server ready for production use.
If you want to forego the extra reading and get right to the AWS SFTP S3 combination, skip ahead to setting it all up!
What Is SFTP
SFTP stands for Secure FTP (File Transfer Protocol) and is a protocol that runs on top of SSH typically accessed on port 22. Because it leverages SSH as the file transfer technology, users can be authenticated against these types of servers by using a username and a password and/or a public/private key pair. This type of authentication can be far more secure than a standard username and password combination found on most servers.
Features of AWS
Amazon Web Services (or “AWS”) offers a wide variety of products in the Infrastructure-, Platform-, and Software-as-a-Service (IaaS, PaaS, and SaaS) spaces that aid tremendously in your team’s DevOps environment. One of the biggest features that AWS provides that we will be leveraging for the setup of the SFTP server is the inherent resiliency in AWS’ services, specifically that which is found in their storage service, S3, and Availablity Zones (“AZs”).
This article does not dive into the nitty-gritty of setting up an AWS account or the details of S3, but we will link you to appropriate resources as needed.
S3 Storage and AWS SFTP
Amazon’s Simple Storage Service (“Amazon S3“) is a block-storage system that can easily store petabytes of data at a very low cost — $0.02 per month per GB, at the time of this writing.
Data availability is of utmost importance when dealing with any kind of FTP server, and this is where S3 really shines. Any time an object is uploaded to S3, the service will automatically replicate the saved data to a minimum of three segregated data centers (Availability Zones) offering eleven 9’s of durability in the data you upload. That means that there’s a 99.999999999% chance that your data won’t be lost or corrupted.
Let’s face it, FTP servers can get very cluttered depending on various use cases requiring them in the first place. Automatic data retention policies are another feature built-in to S3 that can be leveraged here without any additional cost. Files can be reclassified after reaching a user-defined age and moved to Amazon’s tape storage equivalent bringing the data storage cost down to $0.004 per month per GB, at the time of this writing. Additionally, files can be set for automatic deletion after reaching a different user-defined age beyond the previously mentioned tape-backup age.
There are many other features offered by S3 that won’t be covered in this article. But, depending on your particular use case, you may be interested to know that file uploads can trigger events (i.e. run custom code against the newly uploaded file, or put a message on a queue for further processing), and data analyzation and reporting can happen directly against the files from their upload location in S3.
AWS’ infrastructure is comprised of regions that are further divided into Availability Zones (“AZs”). For conceptual understanding, each AZ basically boils down to a physical data center where all the servers live. And, the AZs within a region are connected to each other with a private fiber-optic network to minimize latency between the physical locations.
The resiliency of each region in AWS comes from how Amazon selects the physical location of the AZs. Their locations are diversified as much as possible in terms of flood plains each one exists in and the power grid they’re attached to minimizing single points of failure within a region.
High-Availability architecture at AWS suggests that your servers be spread across multiple AZs with a managed elastic load balancer directing traffic to healthy AZs. If some sort of situation or natural disaster arises that brings an AZ down, the resiliency of the region lives on, and the load balancer will shift traffic to the remaining healthy AZs.
TL;DR – Set Up the SFTP Server!
Enough with the AWS sales pitch, let’s get an SFTP server up and running. Strap yourselves in and prepare to launch!
Some code samples will be provided throughout this article. You can find the entire solution including more advanced command line and AWS CloudFormation templates on our GitHub page: https://github.com/sketchdev/aws-sftp.
Create a Safe Place for Your Uploads
One of the main features of this SFTP server is that it will store all uploaded content to AWS’ S3 service. Let’s create the bucket for the files to be saved to.
- Create a bucket in S3 and call it <yourcompany>-sftp
AWS CLI:
aws s3 mb s3://<yourcompany>-sftp
That’s it! Easy-peasy!
If you’re interested in enhanced disaster recovery options (i.e. incremental backups or multi-regional storage support) or business-specific data retention policies (i.e. your company requires data replication across data centers 500+ miles apart), see our tutorial on setting up cross-regional data replication.
Get a Server
An SFTP server requires, well, a server! Follow the official AWS documentation for instructions to launch a new EC2 instance. While getting that EC2 instance running, use some of the settings mentioned below that will need to be in place for our SFTP server to work properly. This article uses Amazon’s base Ubuntu image, but other linux flavors should be fairly compatible with these instructions.
- When selecting the image to launch your server from, we strongly suggest using Ubuntu for the rest of this article’s instructions to fit. You’re welcome to use another flavor of linux, but you may need to slightly alter this article’s commands as you run them.

- When configuring the instance details in the EC2 Launch Wizard, you’ll want to create a new IAM role that gives your server appropriate permissions to the S3 FTP bucket.
- Click Create new IAM Role (this will open a new tab for you)

- Trusted Identity = AWS Service and Service that will use the role = EC2
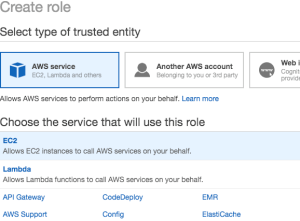
- Proceed to Permissions
- Proceed to Review
- Give the Role a name
- Click Create Role
You should receive confirmation that the role was successfully created and be back on the roles list page at this point - Find and open the role you just created from the list of roles
- Click on “Add inline policy” near the bottom-right

-
- Click the JSON tab to manually create your policy using the following snippet
*be sure to change “<yourcompany>” to your company…more specifically, make sure that chunk matches the name of the bucket you created in the S3 step above:{ "Version" : "2012-10-17", "Statement" : [ { "Effect" : "Allow", "Action" : [ "s3:Get*", "s3:List*", "s3:DeleteObject", "s3:PutObject", "s3:PutObjectTagging", "s3:PutObjectVersionTagging" ], "Resource" : [ "arn:aws:s3:::<yourcompany>-ftp*" ] } ] } - Click Review Policy
- Give it a name
- Click Create
- Close this IAM tab that AWS opened
- Click the JSON tab to manually create your policy using the following snippet
-
- Check this IAM role dropdown for the role you just finished creating. If it does not appear in there, click the refresh icon to the right of the dropdown and check again
- Click Create new IAM Role (this will open a new tab for you)
- Configure your Security Group
- Leave this on the default “Create a new security group” option
- Give your new group a more valuable name and description
- Since SFTP runs over SSH, leaving the default SSH option of port 22 in there is sufficient
- For enhanced security, you can whitelist specific IP addresses in the Source column here of known clients instead of leaving this open to the whole world (0.0.0.0/0). If you do change this, make sure your IP (as seen by the outside world) is allowed access, or you may not be able to proceed with this exercise
- To ensure you have access, choose the “My IP” option in the dropdown under “Source”

Whew, that was a lot more effort than getting that S3 bucket set up. But, in just a few minutes, your server will have launched and will be ready for a little more configuring.
Connect to Your Server
The concepts of connecting to your new server via PuTTY or SSH are beyond the scope of this article. Refer to the official AWS documentation for instructions on that if you are unfamiliar.
Mount S3
S3 is a block-storage system and isn’t intended to be mounted as attached storage out of the box. But, thanks to the open source community, s3fuse is here to save the day! We just need to get it installed on our server.
Install s3fs-fuse
From your initial connection to the server:
- Update and install missing packages
sudo apt-get -y updatesudo apt-get -y install awsclisudo apt-get -y install build-essential libcurl4-openssl-dev libxml2-dev mime-supportsudo apt-get -y install automake autotools-dev g++ git libcurl4-gnutls-dev libfuse-dev libssl-dev libxml2-dev make pkg-config
- Pull s3fuse code down from Github
cd /usr/src/sudo git clone https://github.com/s3fs-fuse/s3fs-fuse.gitcd s3fs-fusesudo ./autogen.shsudo ./configuresudo makesudo make install
Test a Mounted S3 Connection
Okay, time to hold your breath, cross your fingers, and pray that all this stuff works. Nah, of course it works! I’ve been through this numerous times and have a slightly altered version of this setup running in production (see our GitHub page for a fuller-implemented setup of the SFTP server). It’s still worth a test right now to make sure your setup so far is in working condition.
Let’s quickly set up a mount configuration in fstab to see what happens. The syntax of the fstab mount for s3fuse in Ubuntu (as of 16.04, at least) is:
s3fs bucketname:/folderpath /mnt/ftp -o endpoint=region -o iam_role
Execute Test
To test this out, run the following commands:
aws s3api put-object --bucket <yourcompany>-ftp --key ftptest/sudo -imkdir -p /mnt/ftpcat <<EOT >> /etc/fstab<yourcompany>-ftp:/ftptest /mnt/ftp fuse.s3fs _netdev,allow_other,endpoint=us-east-1,iam_role=auto,uid=1000,gid=65534 0 0EOTmount -aecho some testing text > /mnt/ftp/testfile.txtaws s3 ls s3://<yourcompany>-ftp/ftptest/
Verify and Troubleshoot
If all went well, you should see testfile.txt in your S3 bucket (from running that last command). If not, run mount | grep ftp. If you don’t see s3fs on /mnt/ftp type fuse.s3fs, the mount didn’t happen successfully. Retrace your steps and ensure you followed all of the above instructions in this entire article.
Common issues include:
- Not having the IAM policy set up correctly for your bucket
- Not having the IAM role actually attached to the EC2 instance (FTP server)
- Having a different user id on your linux system than what these instructions specified
- Without getting into too much detail about user and group ids, the command on line 5 above specifies
uid=1000,gid=65534, which assumed a couple of things before executing it. Namely, that you’re running the default AWS Ubuntu image. If you aren’t, you may need to alter those ids just for this test. Later on, we’ll work on a script for managing your SFTP users, and that script handles these ids dynamically and won’t be an issue going forward.
- Without getting into too much detail about user and group ids, the command on line 5 above specifies
Cleanup
We made a little mess of our server for this test, so let’s clean that up before proceeding.
- Remove the test text file from S3
rm /mnt/ftp/* - Unmount this test S3 folder
umount /mnt/ftp - Delete the test ftp mount folder
rm -Rf /mnt/ftp/ - Remove the test fstab entry (this command removes the last line of the file)
sed -i '$ d' /etc/fstab - Exit interactive sudo
exit
Set up SFTP on Your Server
If you performed the above steps to test mounting the file system to S3, then you’re already logged on to your server. And, if you’re logged on to your server, that means SSH is already installed and running. And, again, if SSH is installed, so is SFTP; we just have to turn it on!
Create User Group
First off, we need to create a group whose users we will allow SFTP access for. That’s easily done:
sudo groupadd sftpusers
Configure SFTP Settings
SFTP is probably already running if you used the default AWS Ubuntu image, but it’s not using it in a manner in which we’re after. Let’s change some things around a bit.
- Disable the current implementation
sed -i -e 's:Subsystem sftp /usr/lib/openssh/sftp-server:#Subsystem sftp /usr/lib/openssh/sftp-server:g' /etc/ssh/sshd_config - Enable a different implementation and configure its settings
cat <<EOT >> /etc/ssh/sshd_config #enable sftp Subsystem sftp internal-sftp Match Group sftpusers ChrootDirectory %h #set the home directory ForceCommand internal-sftp X11Forwarding no AllowTCPForwarding no PasswordAuthentication yes EOT - Restart the SSH service
service ssh restart
User Setup
Now that we have an SFTP server up and running, we need to set up users that can connect to it. From the section above, we allow users in the “sftpusers” group SFTP access. Any users created belonging to that group should suffice (with a couple of tweaks). Let’s work on building a script to automate the creation of user accounts.
Create a User Account
Create a user account and allows passwords that don’t conform to Ubuntu’s default username policy (Usernames should be lowercase. But if your business case requires upper-cased usernames, the force-badname option allows that). The disabled-password option is used here to prevent the password prompt and allow for a more fluid execution of these commands via the command line.
adduser --disabled-password --gecos "" --force-badname <username>
This next command adds the password to the user account, but it leverages piping the username and password to the command rather than being prompted for it. Again, a good way to execute these commands via a script.
echo "<username>:<password>" | chpasswd
Configure a User's SFTP Environment in AWS
These commands add the user to the “sftpusers” group and makes sure the user isn’t allowed normal ssh login or shell access to the server — we only want them to be able to connect via SFTP kinda like a regular FTP server, but hella-secure.
usermod -g sftpusers <username> usermod -s /bin/nologin <username>
Set up a chroot to the user’s home directory, thus preventing them from browsing any higher directories on the server than their own account. Once logged in via SFTP, as far as the client is aware, /home/<username> is / on the server, and there are no parent directories. This command chunk goes hand-in-hand with the ChrootDirectory command from above.
chown root:<username> /home/<username> chmod 755 /home/<username>
Link the User's Home Directory to S3
Create the directory for the user that will be mounted to S3 via s3fuse. Also, make sure the user has access to their own directory by setting the permissions as needed.
mkdir /home/<username>/uploads chown <username>:<username> /home/<username>/uploads chmod 755 /home/<username>/uploads
Next, create the destination folder in S3. If this doesn’t exist when you try to mount the file system to this location, the mount fails.
aws s3api put-object --bucket <yourcompany>-ftp --key <username>/
Set up the Mount Command
The fstab mount syntax requires the user’s ID and group ID. These commands are acquiring that information and assigning it to two variables to be used in the subsequent set of commands.
usruid=`id -u <username>` usrgid=`id -g <username>`
This last group of commands appends the mount command for this user to the end of /etc/fstab. Make sure that 2nd line does not have any spacing at the front of it; fstab is less than happy when the mount commands begin with any whitespace. You can see that the user and group IDs obtained just prior are used near the end of that mount command.
cat <<EOT >> /etc/fstab <yourcompany>-ftp:/<username> /home/<username>/uploads fuse.s3fs _netdev,allow_other,endpoint=us-east-1,iam_role=auto,uid=$usruid,gid=$usrgid 0 0 EOT
Optional Stuff for AWS SFTP User Account Setup
If you want your SFTP user account to be able to authenticate with a public/private key pair, you can configure this next bit to allow that.
mkdir -p /home/<username>/.ssh echo <pre-generated-public-ssh-key> > /home/<username>/.ssh/authorized_keys chmod 600 /home/$csu_user/.ssh/authorized_keys chown <username>:<username> -R /home/<username>/.ssh
This code sets up the user’s local .ssh folder. When they log on to the server, they can now use their private ssh key as authentication to their account instead of using a password.
Full Script to Create SFTP Users
Below is a full implementation of the create user script. It goes a bit beyond what we covered in this article. For instance, it reads users in from a file to create them, sets up super users that have access to other users’ FTP folders, and allows for overriding (on a user-by-user basis) of the bucket that gets mounted to.
#!/bin/bash
# usage: create_sftp_user <username> <password> <ssh_key> <super_flag> <bucket> <region> <override>
function create_sftp_user() {
csu_user=$1
csu_password=$2
csu_ssh_key=$3
csu_super_flag=$4
csu_bucket=$5
csu_region=$6
csu_override=$7
# create user
adduser --disabled-password --gecos "" --force-badname $csu_user
# set user password
if [ "$csu_password" != "" ]; then
echo "$csu_user:$csu_password" | chpasswd
fi
# prevent ssh login & assign SFTP group
usermod -g sftpusers $csu_user
usermod -s /bin/nologin $csu_user
# chroot user (so they only see their directory after login)
chown root:$csu_user /home/$csu_user
chmod 755 /home/$csu_user
# set up upload directory tied to s3
mkdir /home/$csu_user/uploads
chown $csu_user:$csu_user /home/$csu_user/uploads
chmod 755 /home/$csu_user/uploads
# create matching folder in s3
aws s3api put-object --bucket $csu_bucket --key $userkey/
# get user ids
usruid=`id -u $csu_user`
usrgid=`id -g $csu_user`
# link upload dir to s3
cat <<EOT >> /etc/fstab
$csu_bucket:/$userkey /home/$csu_user/uploads fuse.s3fs _netdev,allow_other,endpoint=$csu_region,iam_role=auto,uid=$usruid,gid=$usrgid 0 0
EOT
# set ssh key if supplied
if [ "$csu_ssh_key" != "" ]; then
mkdir -p /home/$csu_user/.ssh
echo $csu_ssh_key > /home/$csu_user/.ssh/authorized_keys
chmod 600 /home/$csu_user/.ssh/authorized_keys
chown $csu_user:$csu_user -R /home/$csu_user/.ssh
fi
# change s3 location if override flag set
if [ $override -ne 0 ]; then
userkey=`echo $csu_user | sed -e 's/dev//'`
else
userkey=$csu_user
fi
}
# usage: process_users <userfile> <bucket> <region>
function process_users() {
while IFS=, read username pw ssh_key super override_bucket
do
if [ "$override_bucket" == "" ]; then
bucket=$2
override=0
else
bucket=$override_bucket
override=1
fi
create_sftp_user $username $pw "$ssh_key" $super $bucket $3 $override
done < $1
mount -a
}
AWS SFTP Server Host Keys (Optional)
One quirk about using SFTP — which, again, runs on top of SSH — is that when you connect to the server, there’s some client-host secure handshaking going on. In this handshake, not only does the client have to authenticate with the server, BUT, the server also authenticates with the client! This is one of the great security benefits of SFTP over regular FTP/S.
Alas, this poses a problem in a cloudy environment where servers come and go. If our SFTP server flips out and crashes for an unknown reason, we will rely on AWS for launching a new and healthy one to take its place. That’s GREAT! We don’t need to worry ourselves about downtime or being called at 2:00am or troubleshooting and fixing the issue (see “Pets vs Cattle“). However, with a new server comes a new host fingerprint and public keys…things reconnecting clients may view as a hacked or man-in-the-middle server. We need a way to keep the host information consistent.
We’ll configure our server to copy a set of host keys from a secure, centralized location upon launch. This solves our issue of changed keys when the cloud spins up a new server instance for us. Since we’re leveraging S3 for resilient storage of our file uploads, let’s also use it for housing our host keys!
- Create a bucket in S3 and call it <yourcompany>-keys
AWS CLI:
aws s3 mb s3://<yourcompany>-keys - Upload your server’s host keys to <yourcompany>-keys/ftp/
AWS CLI:
aws s3 cp /etc/ssh/ s3://<yourcompany>-keys/ftp/ --recursive --exclude * --include ssh_host* - Update your EC2 User Data start-up script to copy these keys upon launch
cd /etc/sshaws s3 cp s3://<yourcompany>-keys/ftp/ . --recursive --exclude * --include ssh_host*chmod 600 *_keychown root:ssh_keys ssh_host_ed25519_key
We're planning a separate article soon to cover more details about server host keys — the reason for them, how to get them, how to verify them, and other uses for them. Check back with us again soon to learn more about that.
In the meantime, feel free to look into our AWS capabilities, and then let us know if there's anything we can do to help with your AWS SFTP server or Amazon S3 storage.
Tag(s):
Development